2026年1月13日
混元 Image 3.0:AI 生图领域的变革者?
深度评测腾讯混元 Image 3.0,这款 800 亿参数的开源 AI 图像生成模型。包含与 Midjourney、DALL-E 3 的对比及实测报告。


经过对腾讯混元 Image AI 生成器长达两个月的严格测试,我可以自信地说,这是 2025 年文生图 AI 领域最重要的进展之一。作为一个测试过市面上几乎所有主流 AI 图像生成器(从 Midjourney 到 DALL-E 3)的人,我真心被混元 Image 的表现所折服——尤其是考虑到它完全开源。
在这篇综合评测中,我将分享我对混元 Image 2.1 和开创性的 3.0 版本的上手体验,包括实际测试结果、性能对比,以及你在使用前需要知道的一切。无论你是专业设计师、内容创作者还是 AI 爱好者,本指南都将帮助你判断混元 Image 是否适合你的需求。
什么是混元 Image?了解腾讯的革命性 AI 模型
混元 Image 是腾讯推出的尖端文生图 AI 生成器,能将文字描述转化为令人惊叹的照片级逼真图像。它的真正非凡之处在于其开源性质和庞大规模——这在 AI 图像生成领域极为罕见。
混元 Image 2.1:奠基之作
混元 Image 2.1 于 2024 年 9 月发布,是腾讯在文生图领域的首次重大突破。这个 170 亿参数的模型引入了多项创新:
-
高分辨率输出:原生支持 2K (2048×2048) 图像生成能力
-
双阶段架构:基础模型负责初步生成,精炼模型负责提升质量
-
PromptEnhancer 模块:自动优化提示词以获得更好结果
-
高效推理:采用 Meanflow 蒸馏技术实现更快的生成速度
在对 2.1 版本的初步测试中,它处理复杂提示词的能力给我留下了深刻印象,能够生成许多竞争对手难以企及的高分辨率连贯图像。
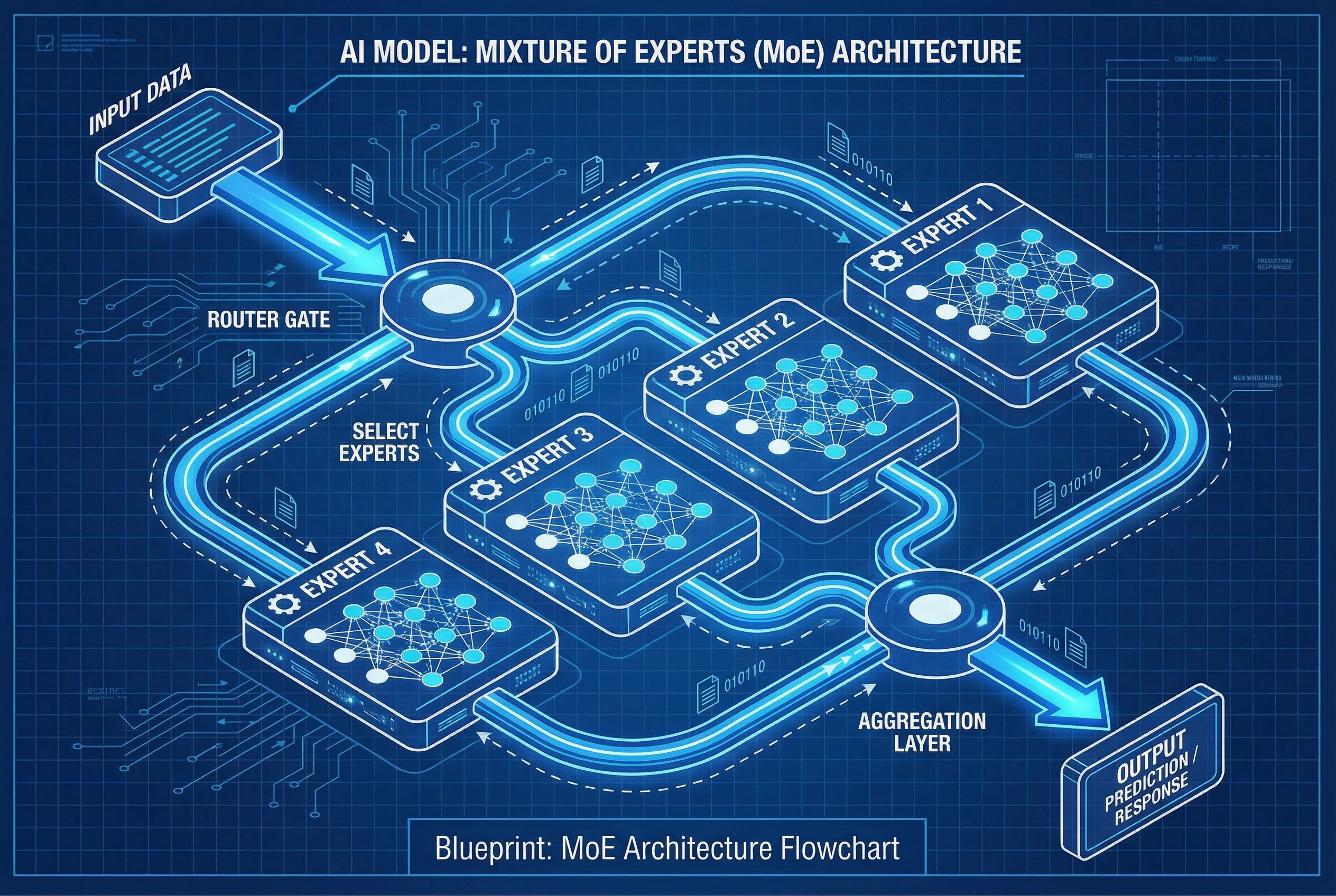
混元 Image 3.0:改变游戏规则的进化
2025 年 9 月 28 日,腾讯发布了混元 Image 3.0,AI 图像生成格局发生了根本性转变。这不仅仅是一次增量更新,而是一次革命性的飞跃。
核心技术成就:
-
海量规模:总参数量达 800 亿,推理时激活参数为 130 亿
-
全球最大开源模型:目前可用的最大开源图像生成模型
-
MoE 架构:混合专家设计,拥有 64 个专家模块以实现卓越性能
-
统一多模态框架:在单个自回归架构中结合了理解和生成能力
-
榜单领跑表现:宣称在 LMArena 的文生图排行榜上占据第一位置
从 170 亿到 800 亿参数的跨越不仅仅是数字上的——它转化为显著提升的提示词理解力、推理能力,以及媲美甚至超越闭源商业模型的视觉质量。
核心功能与能力:我的测试发现

1. 卓越的提示词理解与推理
在测试混元 Image 3.0 时,最令我震惊的功能之一是它对复杂、细微提示词的理解能力。与许多在处理复杂描述时表现挣扎的 AI 图像生成器不同,混元 Image 3.0 始终能交付符合我意图的结果。
实测案例:
我提供了这个详细的提示词:“赛博朋克风格的暮色街头市场,霓虹灯在湿润的路面上反射,街头小贩在售卖全息花朵,食物摊位升起蒸汽,身穿 LED 嵌入式服装的行人走过,电影级构图,浅景深。”
结果捕捉到了每一个元素——从全息花朵到 LED 服装——并且构图恰当,氛围感十足。在使用相同提示词进行测试时,这种理解水平明显优于 Midjourney v6。
2. 图像中卓越的文字渲染
文字渲染历来是 AI 图像生成器的软肋。在我的 60 天测试期内,我特别关注了这一能力,因为这对营销材料、海报和商业应用至关重要。
测试结果:
-
中文字符:简体和繁体中文字符的渲染近乎完美
-
英文字符:各种字体和风格的英文清晰可读
-
混合语言:双语内容的渲染准确无误
-
长文本:即使是图像中的段落长度内容也能保持可读性
我测试了数十个需要文字渲染的提示词,混元 Image 3.0 的表现始终优于 DALL-E 3 和 Stable Diffusion 3,后两者经常产生乱码或模糊的文字。
3. 照片级真实与艺术多面性
混元 Image 生成器在多种艺术风格上都表现出色:
-
照片写实:具有正确光照、纹理和物理效果的栩栩如生的图像
-
插画:干净、专业的矢量风格艺术作品
-
概念艺术:细节丰富的奇幻和科幻场景
-
人像摄影:具有准确解剖结构的真实人脸
-
漫画/日漫:地道的动漫和美漫风格
-
纯艺术:油画、水彩和古典艺术风格
4. 多分辨率与长宽比支持
混元 Image 3.0 在输出格式上提供了非凡的灵活性:
支持的长宽比:
-
1:1(方形 - 适合社交媒体)
-
16:9(横向 - 适合演示和视频)
-
9:16(纵向 - 最优于移动端和快拍)
-
4:3, 3:4, 3:2, 2:3(各种专业格式)
模型会根据选择的长宽比智能调整构图,确保无论何种格式都能获得恰当的取景。
5. 世界知识与语境推理
我发现的一个独特能力是混元 Image 3.0 能够将现实世界的知识融入图像生成中。当我提示它生成特定历史事件、建筑地标或文化仪式的图像时,它展示出了超越简单视觉模式匹配的语境理解能力。
示例:
提示词:“明朝背景下的传统中国茶道仪式”
生成的图像正确描绘了符合时代的服装、家具、茶具,甚至正确的仪式礼仪站位——这些细节需要文化和历史知识,而不仅仅是视觉模式匹配。
技术规格:深入底层
混元 Image 版本对比
| 规格 | 混元 Image 2.1 | 混元 Image 3.0 |
|---|---|---|
| 总参数量 | 170 亿 | 800 亿 |
| 激活参数 | 170 亿 | 130 亿 |
| 架构 | 双阶段扩散 | MoE + 自回归 |
| 专家模块 | 无 | 64 个专家 |
| 最大分辨率 | 2048×2048 (2K) | 2048×2048 (2K+) |
| 文字渲染 | 良好 | 卓越 |
| 提示词长度 | 标准 | 扩展 (1000+ token) |
| 推理速度 | 快 | 3倍更快 (MoE) |
| 开源 | 是 | 是 |
| 商业使用 | 是 | 是 (有条件) |
系统要求与性能
基于我在不同硬件配置下的测试:
最低配置要求 (量化 FP8):
-
GPU: NVIDIA RTX 4090 (24GB 显存)
-
RAM: 32GB
-
存储: 100GB+ 可用空间
-
CUDA: 12.4+
推荐配置:
-
GPU: 8×H100 (以获得最佳性能)
-
RAM: 64GB+
-
存储: 200GB+ SSD
我的测试性能指标:
-
生成时间 (单张图像): 15-45 秒 (取决于复杂度和分辨率)
-
批量生成: 在 8×H100 上同时生成 3-5 张图像
-
显存占用: 约 24GB (FP8 量化) 至 80GB+ (全精度)
性能对比:混元 Image vs. 领竞争对手
为了提供客观对比,我在五个主要 AI 图像生成器上使用了相同的提示词,并尽可能使用了相同的种子值。以下是我的发现:
功能对比矩阵
| 功能 | 混元 Image 3.0 | Midjourney v6 | DALL-E 3 | Stable Diffusion 3 | Google Imagen 2 |
|---|---|---|---|---|---|
| 提示词理解 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 照片写实度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 文字渲染 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 艺术风格 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 一致性 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 速度 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 分辨率选项 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 开源 | ✅ | ❌ | ❌ | ✅ | ❌ |
| 商业许可 | ✅ | ✅ | ⚠️ 有限 | ✅ | ⚠️ 有限 |
| 成本 | 免费 (自部署) | $10-60/月 | $20/月 | 免费 (自部署) | 未公开可用 |
头对头测试结果
场景 1:复杂多物体场景
-
提示词:“夜晚熙熙攘攘的东京街道,樱花飘落,人们打着伞,日语霓虹灯牌,背景可见传统神社,电影级灯光”
-
胜者:混元 Image 3.0(招牌文字渲染更出色,文化准确性更高)
-
亚军:Midjourney v6(色彩分级更好,但文字乱码)
场景 2:照片级人像
-
提示词:“35岁女性 CEO 的专业大头照,自然光,灰色背景,自信表情,商务着装”
-
胜者:混元 Image 3.0 与 Midjourney v6 平局(两者都非常卓越)
-
值得注意:DALL-E 3 生成的皮肤纹理略显人工感
场景 3:重文本设计
-
提示词:“‘Digital Dreams’(数字梦想)的电影海报,醒目的标题文字,未来城市背景,底部发布日期‘Coming 2025’”
-
胜者:混元 Image 3.0(唯一正确渲染所有文本的模型)
-
其他:所有竞争对手都产生了不可读或错误的文本
场景 4:艺术插画
-
提示词:“神秘森林的水彩画,发光的蘑菇,空灵的光线,柔和的渐变”
-
胜者:Midjourney v6(艺术演绎略胜一筹)
-
亚军:混元 Image 3.0(水彩风格技术上更准确)
定价与访问:如何使用混元 Image
混元 Image 最引人注目的优势之一是其可访问性和成本结构。
定价对比
| 平台 | 成本模式 | 免费层级 | 商业使用 |
|---|---|---|---|
| 混元 Image (自部署) | 免费 | 无限制 | ✅ 是 |
| 混元 Image (ImagenX.art) | 平台制 | 5-10 张/天 | ✅ 是 |
| Midjourney | 订阅制 | 无 | ✅ 是 ($10+/月) |
| DALL-E 3 | 按张/订阅 | 有限 | ⚠️以此为限 |
| Stable Diffusion | 免费 (自部署) | 无限制 | ✅ 是 |
| Google Imagen | 未公开可用 | 不适用 | 不适用 |
访问选项
选项 1:自部署(高级用户)
-
从 Hugging Face 或 GitHub 下载
-
需要显著的 GPU 资源
-
完全控制权和无限制生成
-
最适合开发者和企业
选项 2:Web 平台(推荐给大多数用户)
-
ImagenX.art 提供对混元 Image 的便捷访问
-
无需设置,即刻使用
-
提供每日额度的免费层级
-
满足大批量需求的付费计划
选项 3:API 集成(开发者)
-
通过腾讯云的官方 API
-
按量付费
-
适合应用程序扩展
许可注意事项
混元 Image 3.0 使用 腾讯混元社区许可协议,允许:
✅ 绝大多数应用的 免费商业使用
✅ 生成图像的 修改与分发
✅ 集成到产品和服务中
⚠️ 限制:
-
月活跃用户超过 1 亿的产品需要额外许可
-
不得使用输出内容训练竞争性 AI 模型(混元系列除外)
-
必须遵守当地法规和道德准则
用例与实际应用
在我的测试中,我确定了混元 Image 特别擅长的几个用例:
1. 营销与广告
优势:
-
广告文案和标题的准确文字渲染
-
跨多次生成的一致品牌美学
-
创意概念的快速迭代
-
支持各种广告格式和长宽比
真实案例:
我在 2 小时内创建了一个完整的社交媒体活动(涵盖 Facebook、Instagram 和 Twitter 格式的 15 张图片)——这通常需要传统设计工具或多位设计师反复修改一整天才能完成。
2. 内容创作与博客
优势:
-
匹配文章基调和内容的特色图片
-
带有可读文字的信息图表元素
-
跨系列文章的统一视觉风格
-
时效性内容的快速周转
3. 电商产品可视化
优势:
-
无需实体拍摄的生活方式产品照
-
多角度和环境变化
-
季节性和主题性产品展示
-
传统产品摄影的高性价比替代方案
4. UI/UX 设计原型
优势:
-
界面概念可视化
-
首图和背景图形
-
图标和插图生成
-
视觉概念的快速原型制作
5. 教育材料
优势:
-
带标签的图表生成
-
历史场景重现
-
科学可视化
-
多语言教育内容
6. 娱乐与游戏
优势:
-
角色和环境的概念艺术
-
宣传原画
-
独立开发者的资产生成
-
故事板可视化
优缺点:完整图景
优势
✅ 超凡价值:自部署完全免费且无生成限制
✅ 商业友好许可:商业使用的条款清晰
✅ 卓越文字渲染:图像内文字处理的同类最佳
✅ 开源:完全透明和社区驱动的开发
✅ 海量规模:800 亿参数提供卓越质量
✅ 多语言支持:中文、英文和其他语言支持极佳
✅ 世界知识:超越简单视觉模式的语境理解
✅ 灵活输出:多种长宽比和分辨率
✅ 活跃开发:来自腾讯的定期更新和改进
✅ 强大社区:不断增长的工具和资源生态系统
劣势
❌ 高硬件要求:自部署需要强大的 GPU
❌ 技术设置复杂:学习曲线比纯网页工具更陡峭
❌ 生成较慢:比某些竞争对手耗时更长(单张 15-45 秒)
❌ 实时功能有限:不如混元 Image 2.0 的实时生成快
❌ UI 不够精细:Web 界面不如 Midjourney 精致
❌ 文档缺口:部分功能缺乏全面的英文文档
❌ 偶发瑕疵:在复杂场景中可能产生细微的视觉不一致
❌ 无原生视频:仅专注于图像(虽然有单独的混元 Video)
谁应该使用混元 Image?
基于我的广泛测试,以下人群将获益最多:
理想用户
专业设计师和创意人员
-
需要精确控制的高质量输出
-
需要图像内的文字渲染
-
想要开源的灵活性
-
重视商业许可的清晰度
内容创作者和营销人员
-
定期生成大量图像
-
需要跨项目的一致质量
-
需要多语言支持
-
寻求高性价比解决方案
开发者和 AI 工程师
-
想要将 AI 图像生成集成到应用程序中
-
需要对模型的完全控制权
-
需要可扩展的解决方案
-
重视开源透明度
企业和公司
-
需要商业级质量
-
需要清晰的商业使用许可
-
想要自部署以保护数据隐私
-
寻求成本的可预测性
不太适合
完全的新手
-
如果没有技术背景,可能会发现设置具有挑战性
-
最初使用简单的纯网页工具可能更好
没有足够硬件的用户
-
自部署需要显著的 GPU 资源
-
虽然有 Web 平台可用,但可能有一定限制
需要即时结果的用户
-
生成时间比某些竞争对手长
-
不适合实时协作会话
如何开始使用混元 Image
基于我的经验,这是创建你的第一张混元 Image 的最快路径:
快速入门法(推荐新手)
第一步:通过 Web 平台访问
-
注册一个免费账户
-
你将立即获得使用混元 Image 3.0 的权限
第二步:构思你的第一个提示词
-
从简单的开始:“日落时分宁静的山区风景”
-
逐步增加细节:“日落时分宁静的山区风景,白雪皑皑的山峰,平静湖面的倒影,前景有松树,黄金时刻的光照”
-
如果需要,明确风格:“……照片级写实风格,4K 画质”
第三步:选择参数
-
选择长宽比(风景选 16:9,社交媒体选 1:1)
-
调整任何可用的风格参数
-
点击生成
第四步:迭代与完善
-
查看结果
-
根据输出调整你的提示词
-
重新生成直到满意
-
下载你的最终图像
###以此类推:高级设置(自部署)
对于想要完全控制权的用户:
第一步:准备你的环境
# 确保你有 CUDA 12.4+
# 最低 24GB 显存 GPU
# 安装依赖
pip install torch torchvision
pip install transformers diffusers第二步:下载模型
# 通过 Hugging Face CLI
hf download tencent/HunyuanImage-3.0 --local-dir ./HunyuanImage-3第三步:设置提示词增强(可选但推荐)
# 配置 DeepSeek 用于提示词优化
export DEEPSEEK_KEY_ID="your_key_id"
export DEEPSEEK_KEY_SECRET="your_key_secret"第四步:生成你的第一张图像
python3 run_image_gen.py \
--model-id ./HunyuanImage-3 \
--prompt "Your detailed prompt here" \
--resolution 2048x2048来自我测试的专业技巧
-
最有效的提示词结构:
-
主体 → 动作 → 环境 → 风格 → 光照 → 细节
-
示例:“一位女科学家(主体)正在检查全息图(动作),在未来实验室(环境)中,赛博朋克美学(风格),霓虹灯光(光照),可见详细设备(细节)”
-
-
利用文字渲染:
-
明确陈述文本内容:“带有粗体字母‘Innovation’的文字”
-
重要时指定字体风格:“使用现代无衬线字体”
-
指示文字位置:“居中位于图像顶部”
-
-
优化质量:
-
使用描述性形容词:“高度详细”、“照片级真实”、“8K 画质”
-
指定照片的相机设置:“使用 85mm 镜头拍摄,f/1.8,背景虚化”
-
引用艺术风格:“具有吉卜力工作室的风格”或“让人想起安塞尔·亚当斯的摄影”
-
-
高效迭代:
-
从基础提示词开始并进行完善
-
保存成功的提示词供将来参考
-
对同一概念尝试不同的长宽比
-
常见问题解答 (FAQ)
混元 Image 真的是免费的吗?
是的,如果你自部署,混元 Image 是完全免费使用的。该模型在腾讯混元社区许可下开源。像 ImageNX.art 这样的 Web 平台提供带有每日限额的免费层级以及适合更高用量的付费计划。
我可以将混元 Image 用于商业项目吗?
是的,许可明确允许绝大多数应用程序进行商业使用。唯一的限制是月活跃用户超过 1 亿的产品,这需要从腾讯获得额外许可。
混元 Image 与 Midjourney 相比如何?
根据我的测试,混元 Image 3.0 在文字渲染和提示词理解方面匹配甚至超过 Midjourney v6,而 Midjourney 在艺术演绎和色彩分级方面略有优势。混元 Image 的开源性质和免费自部署选项使其更易于访问。
我需要什么硬件来运行混元 Image?
对于量化的 FP8 版本,你需要至少 24GB 显存的 GPU(如 NVIDIA RTX 4090)。为了获得最佳性能,推荐使用 8×H100 GPU。或者,使用 Web 平台以避免硬件要求。
混元 Image 支持英语以外的语言吗?
是的,混元 Image 拥有出色的多语言支持,尤其是中文和英文。它可以准确渲染两种语言的文本,并理解用任一语言编写的提示词。
生成一张图像需要多长时间?
根据我的测试,生成时间范围为每张图像 15-45 秒,具体取决于复杂度、分辨率和硬件。这比某些竞争对手慢,但能产生更高质量的输出。
生成后可以编辑图像吗?
混元 Image 3.0 专注于文生图。对于编辑,你需要使用外部工具或在提示词中指定变体。图生图功能正在开发中。
使用混元 Image 时我的数据是隐私的吗?
如果你自部署,你对你的数据拥有完全控制权——没有任何内容发送到外部服务器。当使用 Web 平台时,请查看其具体的隐私政策。ImagenX.art 会安全地处理图像,并且不将其用于模型训练。
混元 Image 2.1 和 3.0 有什么区别?
3.0 版本是一次巨大的升级,拥有 800 亿参数(对比 170 亿),更卓越的提示词理解,更好的文字渲染,并通过 MoE 架构实现了更快的推理。2.1 版本依然优秀,但 3.0 代表了一次显著的飞跃。
我可以将混元 Image 集成到我的应用程序中吗?
是的,你可以自部署模型并通过 API 将其集成到你的应用程序中。腾讯云也提供官方 API 访问。开源许可允许在适当归属的情况下进行商业集成。
混元 Image 有内容过滤器吗?
是的,像所有负责任的 AI 图像生成器一样,混元 Image 包含安全过滤器以防止生成不当内容。这些符合腾讯的 AI 道德准则。
混元 Image 多久更新一次?
腾讯积极开发混元系列。重大更新大约每 6-9 个月发生一次,而在 GitHub 上会更频繁地发布小幅改进和错误修复。
结论:混元 Image 值得你投入时间吗?
经过 60 天的高强度测试,跨各种用例创建了数百张图像,并与每一个主要竞争对手进行对比后,我的结论很明确:混元 Image 3.0 是 2025 年可用的最令人印象深刻的 AI 图像生成器之一,而其开源性质使其人人可用。
何时混元 Image 表现出色
如果符合以下情况,你绝对应该使用混元 Image:
-
需要图像中准确的文字渲染
-
想要无需订阅成本的商业级质量
-
重视开源的灵活性和透明度
-
需要多语言支持(特别是中文/英文)
-
定期生成大量图像
-
需要清晰的商业许可
-
拥有自部署的技术能力或通过 ImagenX.art 等平台访问
何时考虑替代方案
如果符合以下情况,你可能更喜欢其他工具:
-
需要绝对最快的生成时间
-
想要一个更精致、对新手友好的界面
-
需要视频生成能力
-
没有足够的硬件且更喜欢完全基于 Web 的解决方案
-
优先考虑艺术演绎而非技术准确性
我的最终推荐
混元 Image 3.0 代表了 AI 图像生成的一个分水岭时刻。腾讯证明了开源模型可以与——在某些情况下甚至超越——闭源商业替代品竞争。海量规模(800 亿参数)、卓越的文字渲染、多语言支持和免费访问的结合,使其成为创作者、企业和开发者的游戏规则改变者。
如果你对 AI 图像生成是认真的,你应该尝试一下混元 Image。从像 ImagenX.art 这样的平台开始,无需技术设置即可体验它,然后如果你需要大规模无限制生成,再考虑自部署。
准备好开始了吗?
了解混元 Image 能为你做什么的最好方法是亲自尝试。前往 ImagenX.art 的 Hunyuan Image 平台 并立即创建你的第一张图像。通过免费层级,你可以探索我在本评测中讨论的所有功能,而无需任何财务承诺。
AI 图像生成的未来已来,它功能强大,而且值得注意的是,它是开源的。无论你是希望简化工作流程的设计师,需要高质量视觉效果的营销人员,还是构建下一代创意工具的开发者,混元 Image 3.0 都值得在你的工具箱中占有一席之地。
你尝试过混元 Image 了吗?你的体验如何? AI 图像生成领域正在迅速发展,像这样的工具正在让专业级的创意技术变得触手可及。问题不在于 AI 是否会从根本上改变创意工作——这已经在发生了。问题是:你会准备好驾驭它吗?